
Corresponding TA: Safa Messaoud
Release Date: 11/20/17
Due Date: 12/12/17
In this assignment you will:
Note: Answers without sufficient justification will not recieve any points.
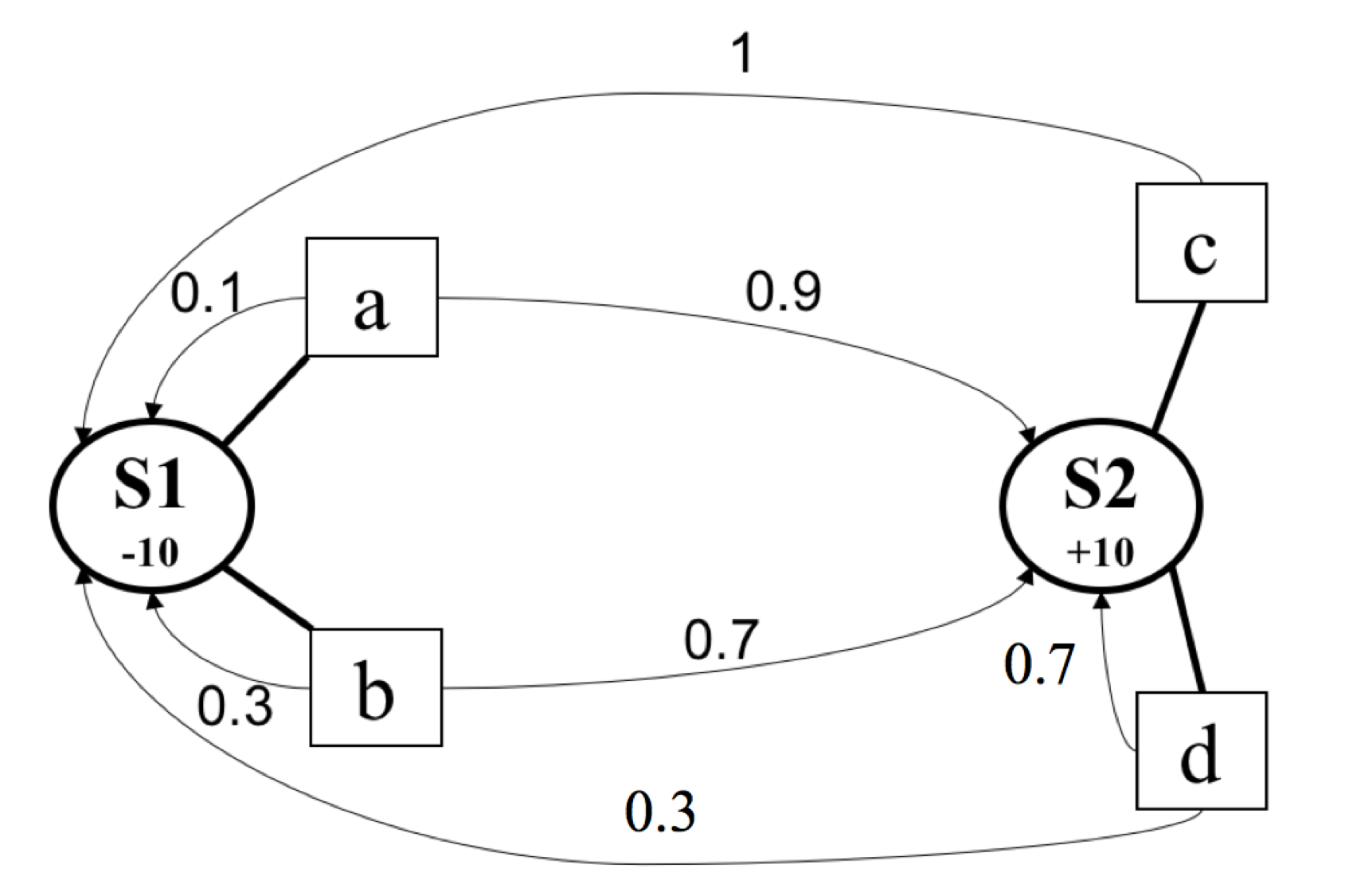
Consider the MDP with two states and represented in the figure below. In , the agent can perform either action or action . In , the agent chooses between actions and action . and are associated with rewards and , respectively.
In this part, you will train an AI agent to play the Pong game with two different methods, namely Q-learning and policy gradient. On the low level, the game works as follows: we receive the last 4 image frames which constitute the state of the game and we get to decide if we want to move the paddle to the left, to the right or not to move it (3 actions). After every single choice, the game simulator executes the action and gives us a reward: either a +1 reward if the ball went past the opponent, a -1 reward if we missed the ball and 0 otherwise. Our goal is to move the paddle so that we get lots of reward.

This homework requires: python3, Tensorflow and pygame. Reuse the virtual environment from MP1.
This exercise requires you to use Q-Learning to train a convolutional neural networks for playing the Pong game. We consider the deep Q-netweork in the figure below. Follow the instructions in the starter code to fill in the missing functions. Include a learning curve plot showing the performance of your implementation. The x-axis should correspond to number of time steps and the y-axis should show the reward. Your agent should be performing well after 4-5m steps.
Relevant File: q_learning.py
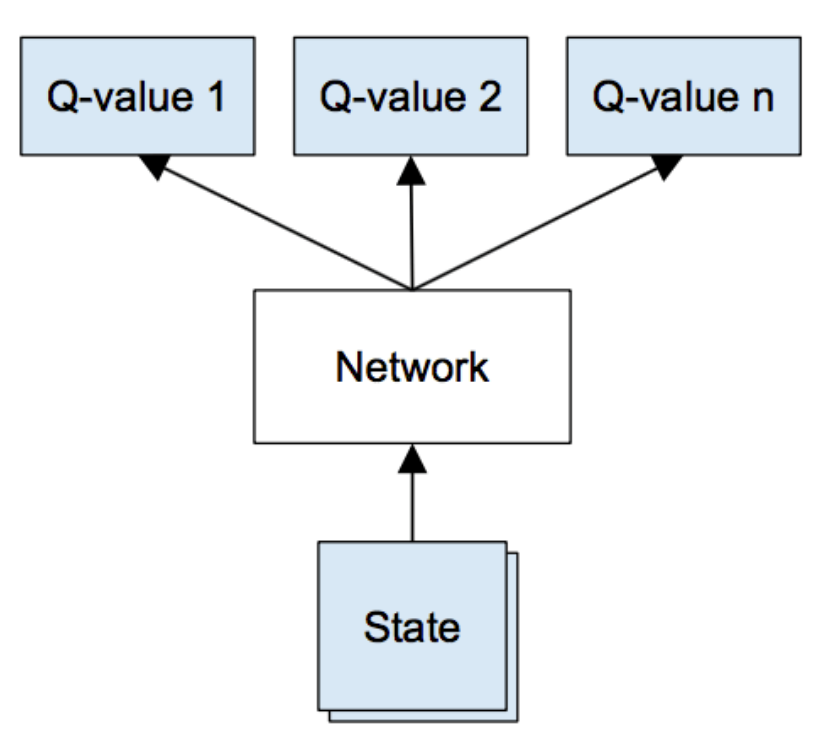
This exercise requires you to use Policy Gradient to train a convolutional neural networks for playing the Pong game. In this case, the network produces a probability distribution over the set of possible actions . After the end of every episode, we label the actions that were taken in this episode with the obtained final reward (+1 if we win and -1 if we lose). Then, we compute the discounted reward for every action. The resulting score is used to compute the policy gradients with respect to the parameters of the convolutional network, i.e. . Follow the instructions in the starter code to fill in the missing functions. Include a learning curve plot showing the performance of your implementation. The x-axis should correspond to number of time steps and the y-axis should show the reward. Your agent should be performing well after 4-5m steps.
Relevant File: policy_gradient.py
Submitting your code is simply commiting you code. This can be done with the follow command:
svn commit -m "Some meaningful comment here."