Et Tu Brute
Learning Objectives
- File Descriptors
- Pipes
- Forking with Pipes (IPC)
- Reading and Writing from Pipes
- Process-level parallelism
Backstory
You are an intern for Marcus Junius Brutus.
Brutus is planning the assassination of Julius Caesar, dictator of the Roman Senate. In order to do so he must know the exact whereabouts of Caesar and when he will be most vulnerable.
A visitor who claims to be from the future gives you a file journal that has all of this information. The visitor has encrypted the journal to avoid the information from falling into the wrong hands. He warns Brutus to read it with discretion. The journal is encrypted with a caesar cipher, which has a well known solution for breaking it and decrypting the cipher.
Your fellow interns are already aware of the techniques for breaking the encryption, so you do not need to worry about it. There is a catch. Caesar is well aware of these decryption techniques as well, so he encrypts every line of the journal with an arbitrary shift amount. To make matters worse, your fellow slaves interns who are brute forcing all the possible ciphers take long naps and the journal only documents Caesar’s whereabouts for the next couple of days. This means time is of the essence. So in order to decrypt the journal in time, Brutus has asked you to assign each line of the journal to an intern to decrypt. At the end you will stitch all their work together and write it to a new journal for Brutus to read.
Simple right? Except that some lines are longer than others, you need to wait for all the interns to finish, and you need to write it all back in order for it to make sense to Brutus.
Files
- cipher.h - header file for the decryption library.
- Makefile - the makefile you should use to build.
- journal.txt - a newline separated journal that you must decrypt.
- brutus.c - main file which will contain your implementation for brute forcing caesar ciphers.
Usage
./brutus <input_file_path> <output_file_path>For example
./brutus input.txt output.txtReference: Single Process Version
It is quite simple to do the decryption in single process version. First we read from file. For each line we read, we call get_most_likely_printout() and get decrypted line.
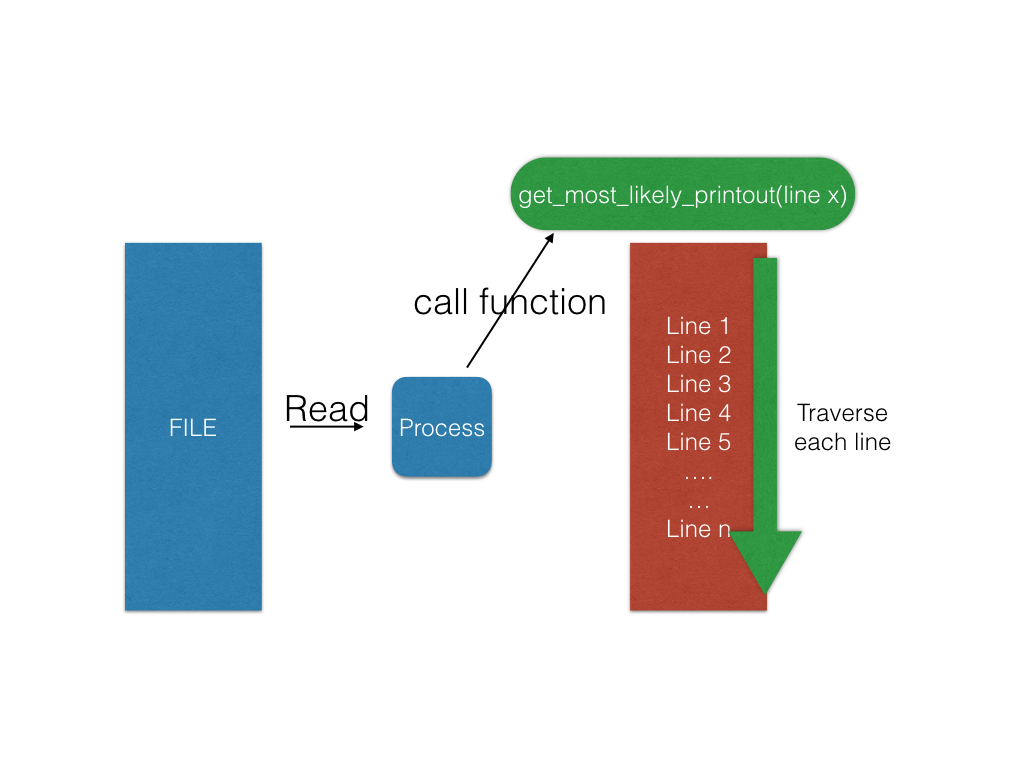
Mission: Can we do it in time?
Decryption in real life is usually slow and therefore single process version cannot complete the job in time. We can use process-level parallelism to solve this problem. We can assign each line to one child process and ask them to finish their job. In order to gather decryptions from children, we need a way to do IPC(Inter Process Communication). We can use pipes to achieve this. Following are instructions to help you complete the mission.
Parse the arguments
This should be done by calling the arg_parse() function.
Note that the input file will always be newline separated.
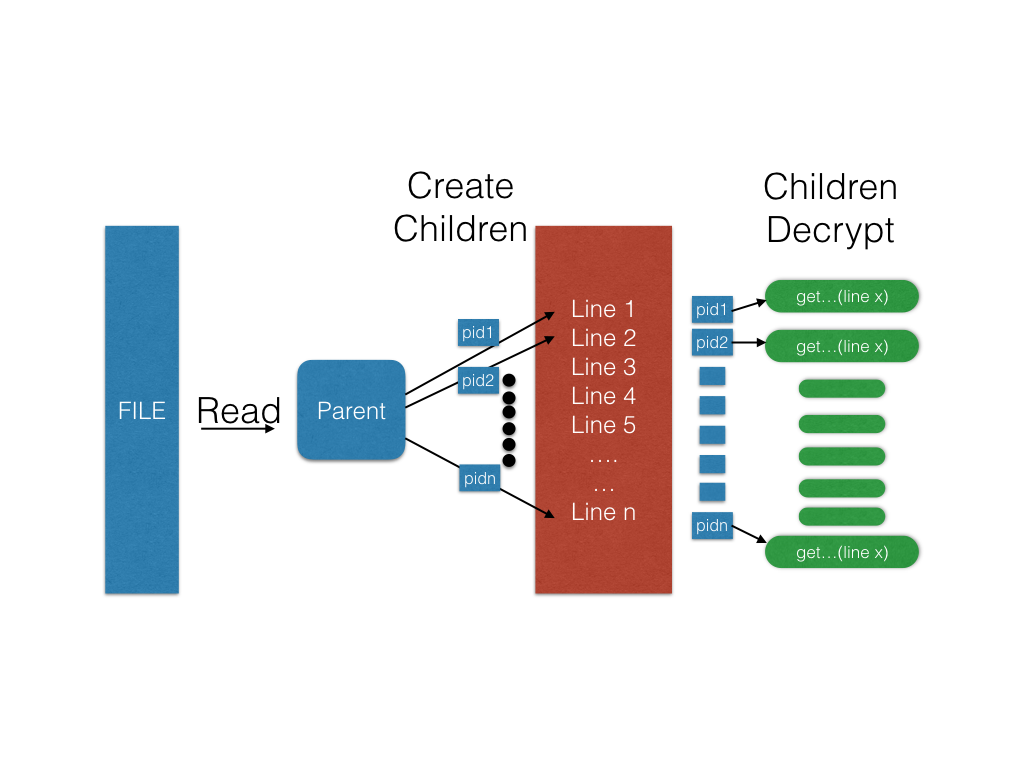
Make 1 pipe (read and write end) and store 1 pid for each child
You will need to do this in order to have Interprocess communication (IPC)
Notice that you should create EXACTLY ONE CHILD for EACH LINE
You need one pipe per child, since you need a read end for the parent and a write end for the child.
Assign 1 line to each child process to decrypt
This is where the magic happens. Remember that when forking with pipes, it is common practice to close the unnecessary (unused) end of each pipe in the child and parent process. This is to avoid the awkward scenario where a process is listening to itself. You need to find some way for the parent process to give the line to decrypt to its child. One somewhat hacky solution is to have the parent read the line from the file then fork. The child now has its own copy of the line. Once the child has the line to decrypt, you should have it call on the
get_most_likely_printout()
function from cipher.o. Once your child is done decrypting a line, it should write into the write end of its pipe so that the parent can later read from it. If a child has no more work then it should close all remaining ends to its pipe and exit.
The following is the workflow for the first-half of the program.
Collect the decryptions
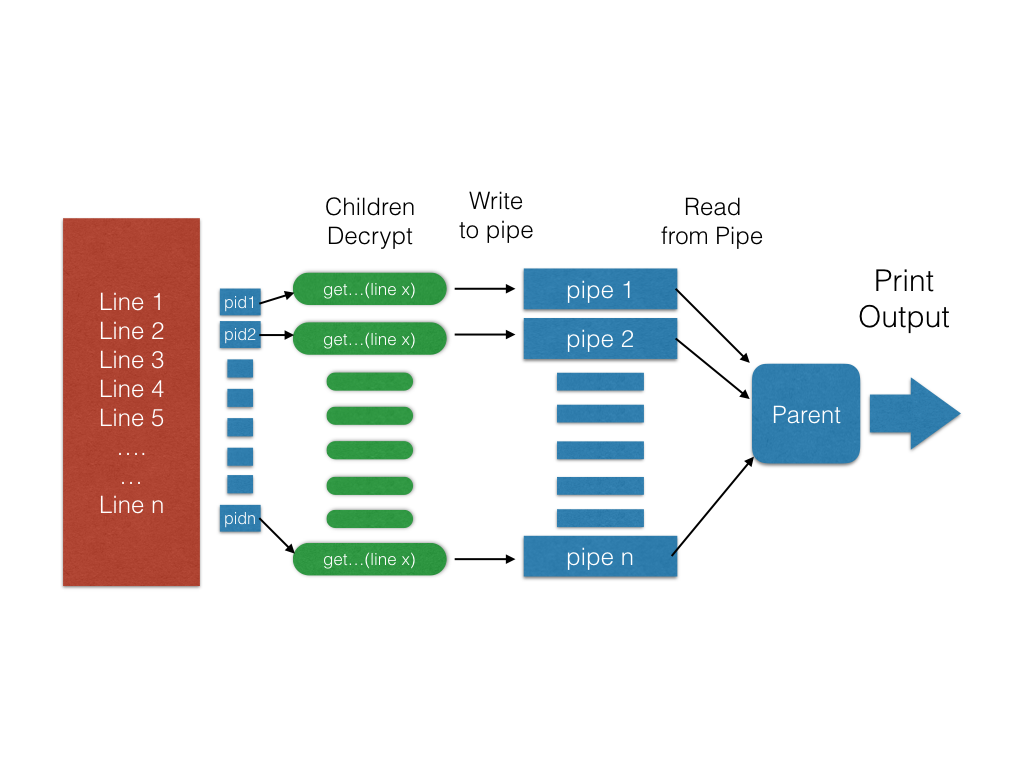
You must wait for you children in this step
Like any responsible parent your parent process should wait on its children. This is where having remembered your children’s’ pids come in handy. Once you are done waiting for all your children to finish you can start reading from your pipes sequentially. ### Write all the decryptions to a file Now that you have all your children’s print outs you can write them to the output file in the same order as the lines in the original file. You should write exactly what you read from your children and not a single byte more.
The following is the workflow for the second-half of the program
Hints
What can I do with fcntl?
int fcntl(int fd, int cmd, ... /* arg */ );
We can do a lot of things on a file fd by using the function fcntl. The operations includes duplicating file descriptor, retrieving file status, and many operations. If you are interested you can find reference here.
How can I use it?
In this lab, we want you to learn how to change the capacity of a pipe. A pipe has limited capacity and writing to a full pipe might be blocked or failed.
Then how can this be useful? Remember in this lab, you need to:
- Let each child process decrypts a line and write to a pipe.
- Let parent process wait for all child processes to finish their job and then collect the decryptions.
Now, if some lines are too long, processes decrypting the lines cannot return from their write operation and have to wait for the parent process to read something out from their pipes. However, the parent process will be waiting for all its children until they finish their job. What concurrent programming situation did we hit here? ;-)
The following is a picture to help you understand this problem. Notice that pipe 2 and some other pipes are full (marked as red). Therefore, process pid2 is blocked on write and waits for the parent process to read some bytes from its pipe pipe2. However, the parent process is waiting for all its children and won’t move on to next step (read from pipe).
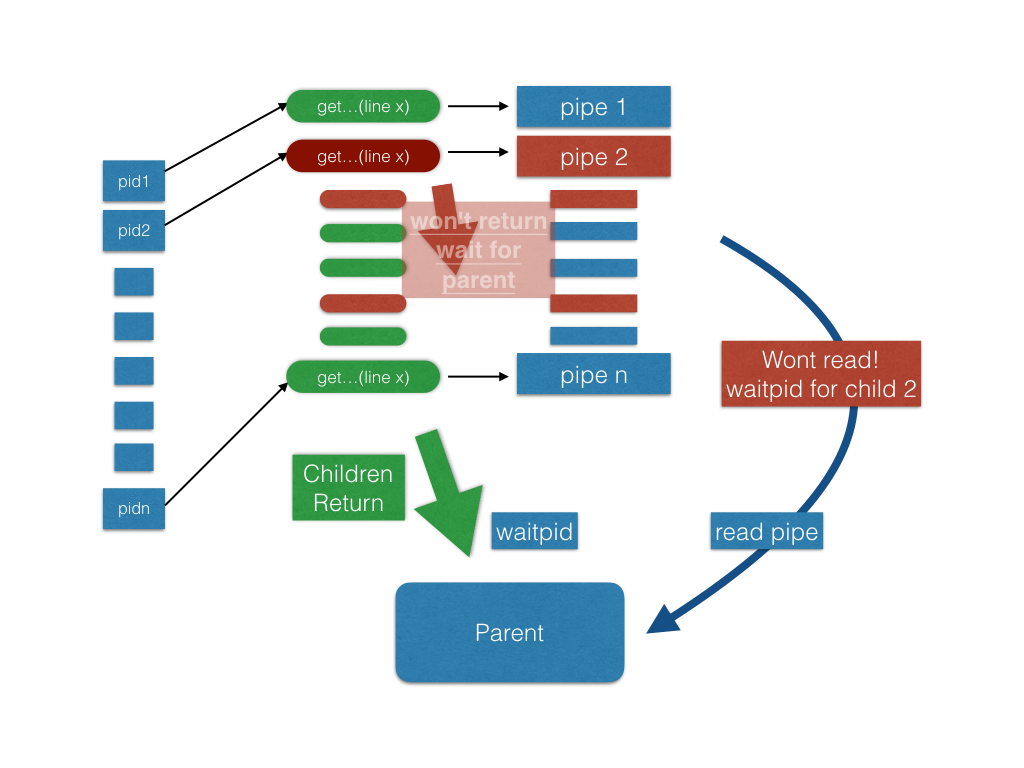
Solution
We can set the size of the pipe according to the length of the longest line in the file. Then there will be no blocking issue.
What can I do with arg_parse
Note that the command line input provided to your program is just the input file to decrypt and output file to write decrypted content to. Before you spawn off child processes to decrypt individual lines, there are several intermediate steps you need to worry about for correctness: * Get the number of lines in the input file * Number of bytes in the longest line of the input file * FILE pointer to the input file * FILE pointer to the output file
If you are not sure why you need the above information, make sure you think about it and convince yourself about their use before moving forward. The arg_parse function implements the required operations to obtain all of the above-mentioned data. It returns void pointer to a pointer with the above data in order that you can read from. You would need to keep the following points in mind about how arg_parse works: * It will prompt the user if they don’t have the right arguments. * It will prompt the user if the input file is not readable. * It will prompt the user if the output file is not writable. * Will rewind() the input file pointer so it can be used to read file content. * It is the callers responsibility to free up any memory and file resources that the caller obtains from calling arg_parse function
Error Cases
As always, you are expected to write test cases to ensure your implementation satisfies all the requirements in specification provided. For this purpose, come up with test cases without looking at your implementation and focusing on points described in specification. Some example cases to think about could include:
- Input to the function: Make sure you have test cases for any problems with input arguments provided to the function. E.g. correct number of arguments were not provided, the input file is empty or not readable, etc.
- Main functionality: Make sure you have basic test cases to make sure your implementation is correctly decrypting the input file content. The actual output file can be compared to an expected output file for example
- Corner cases: There could be several corner cases you could possibly test for. Example corner scenarios to think about could include (please see NOTE below):
- What if duplicate lines are read and you may end up with a mismatch in expected and actual size of output file?
- What if the pipe gets destroyed while it is being used by the parent/child processes.
- What if the one or more of child processes get killed during the process of decryption?
- Can the output file incorrectly be written by multiple processes and result in it’s content being non-deterministic?
- Have you correctly set the pipe size to ensure no deadlock occurs in your implementation?
NOTE: We do not expect you to test for all these corner cases for this lab as implementing them can be quite challenging. However we are listing them out as food for thought. We want you to stretch your minds when thinking about your code quality and be aware of all the possible ways in which your code can be broken. That is the only way to ensure your code is robust, no shortcuts there :) So even though these tests are not required, we would still encourage you to pick one or two that you think are important and implement them.