Activity 7: Bayes' Theorem To Predict Gender
Due: On git by Tuesday, Feb. 28, 2017 at 9:30am
Team: This is a solo assignment.
Grading: This assignment is worth 30 points.
Team: This is a solo assignment.
Grading: This assignment is worth 30 points.
Overview
In lecture, you learned about Bayes' Theorem. Using a large set of names with a known gender, you will use this to predict the gender of Bronze Tablet winners at UIUC.
Initial Files
A new directory has been created on the release git repository, which you should complete this assignment in. To merge this into your repository, navigate to your workbook directory using a command line and run the following commands:
git merge release/exp_activity7 master -m "merge"
Assignment
Create a Jupyter notebook in your activity7 directory. In your activity7 directory, run the following command:
In your activity7 directory, you will find two files:
- bronzeTablet_1925_2013.csv, a CSV of every Bronze Tablet recipient from 1925-2013
- babynames, a folder containing ~100 CSV files containing baby names by their birth year and gender
The goal of this activity is to classify the name of each Bronze Tablet recipient by gender and compute the gender breakdown of the recipients for each year.
It is up to you to decide how to classify their gender (and when to decide if a name is Unisex).
Your choices may result in your result being slightly different than mine,
but our results should be very close:
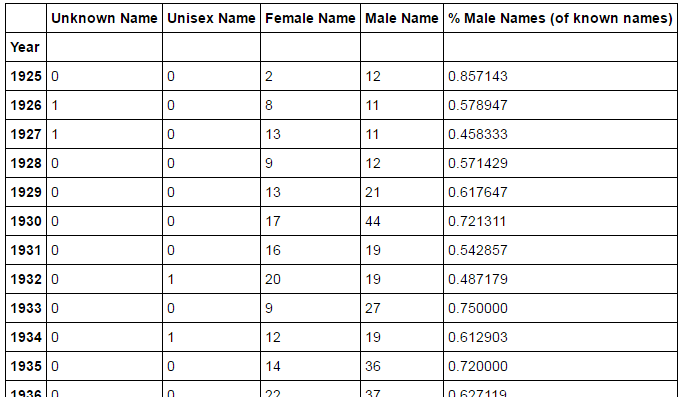
Hint: Reading babynames into a DataFrame
You can read every file in the babynames folder into a single DataFrame with the following code:
for year in range(1910,2011):
fileName = "babynames/yob" + str(year) + ".txt"
df = pd.read_csv(fileName, names=["Name", "Gender", "Count"])
frames.append( df )
df = pd.concat(frames, ignore_index=True)
Note that the read_csv call contains a names
parameter to give the column names (since the CSV does not contain headers).
Hint: Calculating Probability of a Gender
To write a custom function that is applied to every row in a dataset, you can use the apply method on a DataFrame. For example:
In order for the above code to run, a getProbF (the first parameter into apply)
must be defined. This function will receive each row of data as a Series:
# d is each record in our DataFrame
# Example: d["Full Name"] will return each person's full name
# ... your code ...
# Return the value that should be inserted into the row:
return 0.5
Using the two code snippets above will add a pFemale column
to a DataFrame. (Leaving the getProbF function as-is will give every name a
probability of being 50% Female -- you'll want to improve this!)
Submission
This activity is submitted digitally via git. View detailed submission instructions here.